
La trappola della self-correction
Chiedi a un qualsiasi LLM moderno di scrivere una funzione Python e otterrai qualcosa che sembra giusta. Esegui i test e spesso scoprirai che non lo è.
Il riflesso è ovvio: incollare i test falliti nella chat e chiedere al modello di riprovare. È intuitivo, gratis, e qualche volta funziona. Ma ha un soffitto — e il soffitto è il modello stesso. Un modello non può debuggare facilmente quello che non riesce a vedere. I cicli di self-correction tendono a riciclare gli stessi punti ciechi, gli stessi off-by-one, gli stessi edge case dimenticati.
Quindi ci siamo posti una domanda diversa: e se l’LLM fosse solo la prima bozza?
Il codice come materiale evolvibile
Il Genetic Improvement (GI) è una tecnica search-based che tratta i programmi come l’evoluzione tratta i genomi. Muta, ricombina, seleziona, ripeti. È stato usato per correggere bug e ridurre il runtime di sistemi legacy. Noi ci siamo chiesti se potesse salvare anche il codice degli LLM.
L’intuizione è che il codice generato da un LLM è raramente completamente sbagliato. Di solito è strutturalmente sensato — tipi di dato giusti, algoritmo ragionevole — ma con un difetto sottile. Questo lo rende un ottimo seme: probabilmente esistono buoni vicini nello spazio di ricerca, serve solo un modo intelligente per trovarli.
Il problema: mutazioni casuali sul codice sorgente producono quasi sempre roba che non si compila nemmeno. Il nostro trucco è stato vincolare le mutazioni attraverso una grammatica specializzata su ciascun programma.
La pipeline, in tre mosse
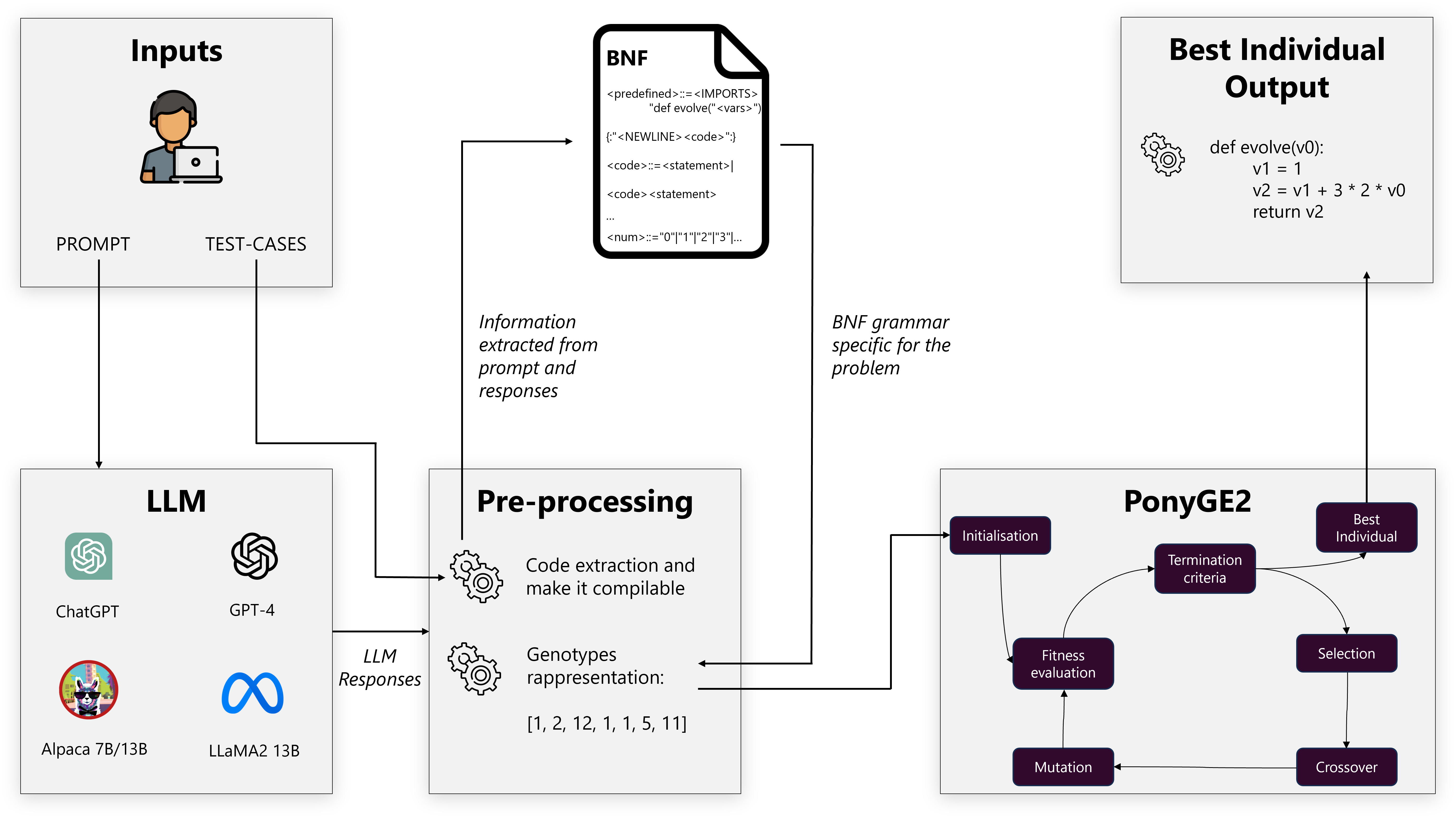
1. Estrai. Tira fuori il vero codice Python dalla risposta verbosa dell’LLM, intrisa di markdown. È più difficile di quanto sembri — i modelli amano avvolgere il codice nella prosa.
2. Specializza. Parsa il codice in un Abstract Syntax Tree, poi automaticamente costruisci una grammatica BNF da quello che vedi. Solo cicli for e interi nell’originale? Allora la grammatica permette solo cicli for e interi. Lo spazio delle mutazioni resta piccolo e sensato.
3. Evolvi. Passa il seme e la grammatica a PonyGE2 e lascia che l’Evoluzione Grammaticale faccia il suo — popolazione di 1.000 individui, fino a 100 generazioni, fitness = frazione di test PSB2 superati.
La grammatica dinamica è la salsa segreta. Una grammatica universale per “tutto il Python valido” farebbe esplodere lo spazio di ricerca; una grammatica scritta a mano sarebbe fragile. Generandola dall’output stesso dell’LLM, usiamo la bozza del modello come conoscenza pregressa su dove probabilmente vive la risposta giusta.
Cosa abbiamo trovato
Abbiamo eseguito tutto questo su 25 problemi del benchmark PSB2 e cinque LLM lungo lo spettro delle capacità: GPT-4, ChatGPT, LLaMA-2, Alpaca-13B, Alpaca-7B. Ogni esperimento ripetuto 30 volte. Test di Wilcoxon dei ranghi con segno per la significatività.
Il riassunto è breve:
- Tutti i modelli sono migliorati. Statisticamente significativo (p < 0.001) ovunque.
- I modelli più piccoli hanno guadagnato di più. Problemi su Alpaca-7B passati da “0 test superati” a “funziona davvero” in molti casi.
- Anche GPT-4 ne ha beneficiato. Guadagni assoluti minori, perché il seme era già forte, ma comunque reali.
- Il GI ha battuto la self-correction. Stesso codice di partenza, stesso feedback dai test — l’evoluzione ha trovato fix migliori di quelli che il modello trovava chiedendoglieli.
Quest’ultimo punto è quello che metterei su un cartellone. La self-correction è limitata dalla rappresentazione del problema interna al modello. La ricerca evolutiva no.
Perché funziona
Tre cose, impilate:
Il seme è abbastanza buono. Gli LLM ti danno la forma giusta della soluzione. Non devi inventare l’algoritmo — devi solo aggiustarlo.
La grammatica focalizza la ricerca. Adattare le mutazioni a quello che il programma effettivamente contiene uccide il 99% dello spazio di ricerca — la parte che non sarebbe mai stata utile.
Le popolazioni non si bloccano. Gli approcci greedy del tipo “correggi quel bug” finiscono in ottimi locali. Una popolazione tiene vive più scommesse e può ricombinare vincite parziali tramite crossover.
Cosa suggerisce
Se metti in produzione codice generato da LLM, questo lavoro suggerisce che la pipeline giusta non è prompt → output → ship. È prompt → output → ottimizza → ship. La fase di ottimizzazione non ha bisogno di un modello più grande o di più token — ha bisogno di un loop di ricerca con una buona funzione di fitness.
E c’è un quadro più grande qui: i metodi neurali ed evolutivi non sono concorrenti, sono complementari. Gli LLM sono veloci, fluenti, creativi; l’evoluzione è paziente, sistematica, orientata al risultato. Combinali, e ottieni qualcosa che nessuno dei due fa da solo.
Reference
Questo post è una sintesi divulgativa di:
Pinna, G., Ravalico, D., Rovito, L., Manzoni, L., De Lorenzo, A. (2024). Improving Large Language Models Code Generation by Leveraging Genetic Improvement. In: Proceedings of the 27th European Conference on Genetic Programming (EuroGP 2024), parte di EvoStar 2024, Aberystwyth, UK, 3–5 aprile.
Ricerca condotta presso l’Università degli Studi di Trieste e la NOVA Information Management School (NOVA IMS), Universidade Nova de Lisboa.