
La parte di una PR che nessuno misura
Quando facciamo benchmark sugli agenti di codifica AI, misuriamo il codice. Compila? Passa i test? È pulito?
Ma una pull request non è un diff. È un diff più una storia. Il reviewer legge il titolo, poi la descrizione, poi forse il codice. La descrizione fissa le aspettative. Dice al reviewer cosa cercare. Se la storia è sbagliata, ogni riga di codice che segue viene letta contro il template sbagliato.
Una PR intitolata “fixed the auth bug” che in realtà refactora il livello del database non solo fallisce a informare. Inganna attivamente. E quando i reviewer captano il mismatch — anche solo a livello inconscio — la fiducia crolla.
Perché gli agenti sono stranamente cattivi in questo
Scrivere codice e scrivere un riassunto onesto di quello che hai appena scritto sono task cognitivi diversi. Il primo è algoritmico. Il secondo è meta-cognitivo — devi sapere cosa intendevi fare, cosa hai provato, e cosa è effettivamente uscito dall’altra parte.
Gli agenti AI sono bravi nel primo. Faticano nel secondo, e il fallimento ha una forma precisa:
- L’agente legge il task e formula un piano.
- Incontra attriti inattesi — test che falliscono, dipendenze strane, edge case.
- Itera, debugga, fa deviazioni, scende a compromessi.
- Il codice finale non è esattamente quello che il piano prevedeva.
- Quando gli viene chiesto di scrivere una descrizione, l’agente spesso descrive il piano, non il risultato.
Da lì nasce l’inconsistenza messaggio-codice. Non malizia. Non pigrizia. Una deriva tra intento e risultato che l’agente non ha mai notato.
Come l’abbiamo misurata
Abbiamo costruito una metrica — PR-MCI, Pull Request Message-Code Inconsistency — che misura la distanza semantica tra quello che dice la descrizione e quello che il diff effettivamente fa. È un punteggio continuo, non sì/no, così possiamo classificare le PR per quanto sono inconsistenti.
Poi l’abbiamo applicata a 23.247 pull request scritte da agenti AI e abbiamo guardato cosa succedeva a quelle inconsistenti.
Il problema dell'1,7%
Solo l’1,7% delle PR ha ottenuto un punteggio di alta inconsistenza. Sembra un non-problema. Non lo è, per due motivi.
Primo, la scala. In un’azienda che spedisce migliaia di PR generate da agenti al mese, l'1,7% sono decine di descrizioni fuorvianti che ogni settimana atterrano nelle inbox dei reviewer.
Secondo, ognuna è costosa.
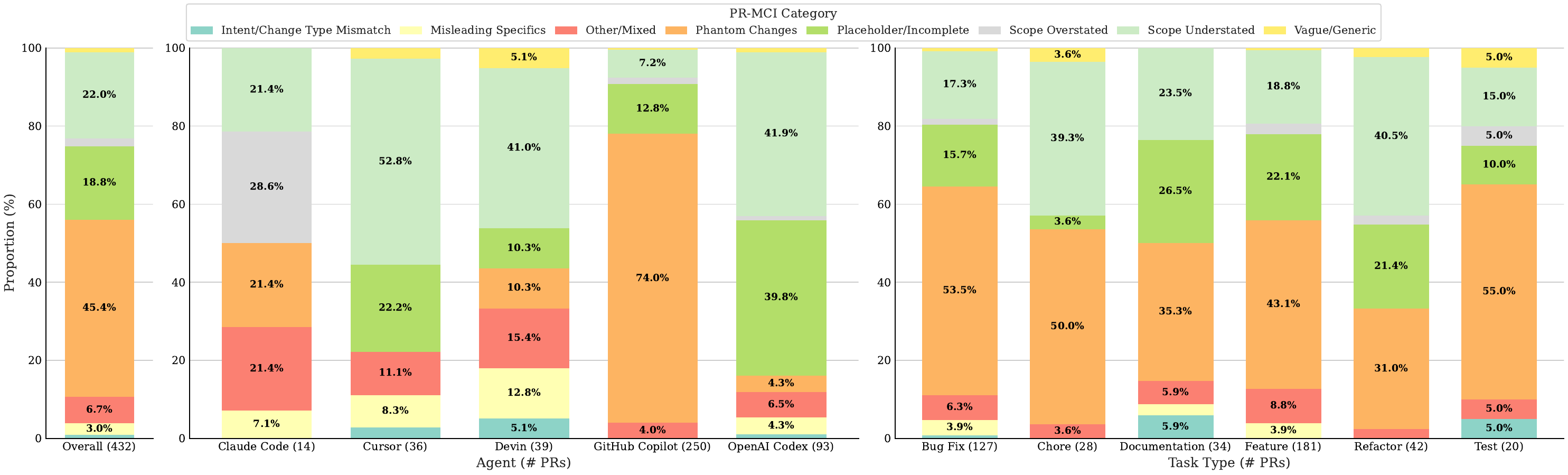
Le PR ad alta inconsistenza:
- Vengono accettate il 51,7% in meno rispetto alle PR consistenti
- Impiegano 3,5× di tempo per il merge quando vengono accettate
- Spesso hanno codice tecnicamente valido — il rifiuto riguarda la storia, non la sostanza
Un reviewer che scopre che la descrizione gli ha mentito non concede il beneficio del dubbio all’agente sul paragrafo successivo, né sul file successivo, né sulla PR successiva. La fiducia si paga in anticipo e si recupera lentamente.
Perché il costo è così alto
Due meccanismi si compongono:
Costo di ri-orientamento. Un reviewer che si aspettava fix all’autenticazione e trova refactoring del database deve buttare via il modello mentale e costruirne uno nuovo. È l’operazione più costosa in code review. Tende anche a far emergere istinti difensivi: “cos’altro c’è qui dentro che non mi aspettavo?”
Contagio della fiducia. Se la descrizione è sbagliata, il reviewer smette di considerarla un riassunto — il che significa che deve leggere il codice con più attenzione di quanta ne avrebbe altrimenti. Ogni PR successiva alla prima inconsistente eredita un piccolo sconto sulla fiducia, soprattutto se viene dallo stesso agente.
Il risultato finale: una piccola percentuale di PR fuorvianti degrada il throughput dell’intera pipeline di review.
Cosa fare
Per chi sviluppa agenti, il fix è strutturale. La descrizione non dovrebbe essere generata dal piano. Dovrebbe essere generata dal diff finale, in un passaggio separato, da qualcosa che non ha visto il task originale. Interventi economici che già aiutano:
- Pass di verifica. Una seconda chiamata LLM legge diff e descrizione e segnala il mismatch.
- Controlli euristici. I file menzionati nella descrizione dovrebbero comparire nel diff. Le categorie di bug citate dovrebbero corrispondere ai test che vengono toccati.
- Rigenerazione della descrizione. Butta via la descrizione che l’agente ha scritto in fase di pianificazione. Generane una nuova solo dal diff finale.
Per i team che usano questi agenti: assumi che le descrizioni siano inaffidabili finché non si dimostra il contrario. Costruisci l’abitudine di scorrere prima il diff, poi la descrizione.
Per il campo: smettete di valutare gli agenti solo sul codice. Una pull request è un deliverable, e la descrizione è parte del deliverable. Un agente che scrive codice corretto con una PR fuorviante non è un buon agente — è un modo veloce per distruggere la fiducia dei reviewer.
La storia vera
Man mano che gli agenti diventano meno assistenti e più collaboratori autonomi, il collo di bottiglia si sposta. Non è se sanno scrivere codice. Sanno. La domanda è se ci si possa fidare che descrivano cosa hanno scritto.
Al momento, sull'1,7% dei tentativi, non si può. E quell'1,7% sta facendo più danni alla relazione tra umani e agenti di quanti ne abbia mai fatto un compile error.
Reference
Questo post è una sintesi divulgativa di:
Pinna, G., Sarro, F., Sutton, C. (2026). Analyzing Message-Code Inconsistency in AI Coding Agent-Authored Pull Requests. In: Proceedings of the 23rd International Conference on Mining Software Repositories (MSR 2026) — Mining Challenge Track.
Ricerca condotta presso la University College London (UCL) e il King’s College London.