
Cosa avevamo lasciato sul tavolo l’ultima volta
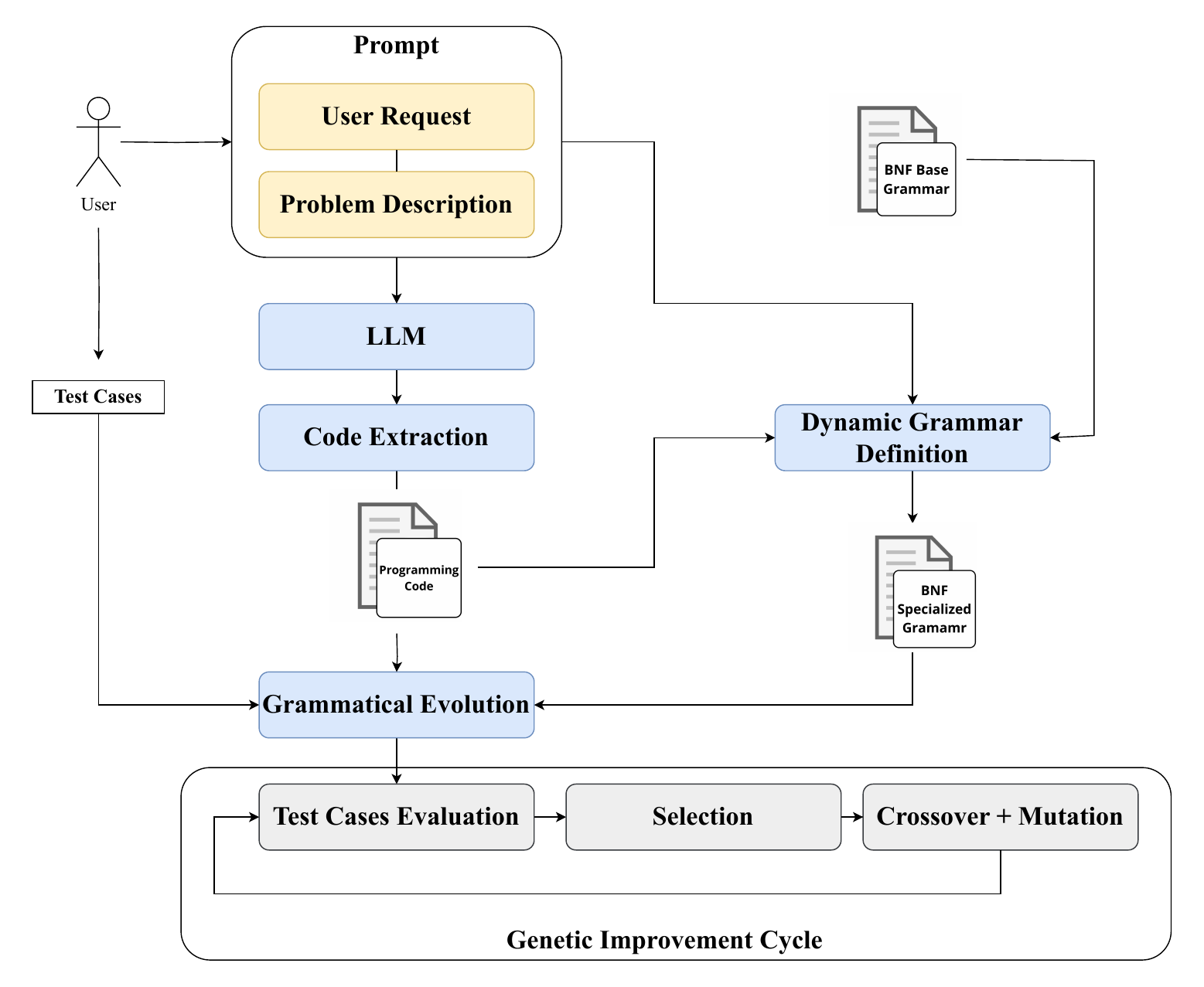
Il paper di EuroGP 2024 ha dimostrato l’idea base: prendi la prima bozza buggata di un LLM, passala alla Grammatical Evolution, ricevi codice migliore. Guadagni statisticamente significativi su ogni modello.
Ma l’evoluzione in sé era grezza. Selezione a torneo. Funzione di fitness binaria. Un budget di ricerca che scalava male con il numero di test case. Avevamo una pipeline funzionante che lasciava vincite per terra.
Questo paper è l’audit. Abbiamo ricostruito tre pezzi del loop GI — selezione, sampling, fitness — e abbiamo chiesto se un’evoluzione più intelligente compra di più.
Risposta breve: sì.
Perché la selezione a torneo è il default sbagliato
La selezione a torneo prende individui con mini-competizioni: ne peschi a caso un gruppo, tieni il migliore. È veloce e facile e ha una debolezza nota — ama i generalisti e uccide gli specialisti.
Questo conta per il codice. Immagina due varianti della bozza di un LLM:
- Variante A: passa il 60% dei test case, fallisce gli altri in modo mediocre.
- Variante B: massimo dei voti su tutti i test sui numeri interi, fallisce sulla manipolazione di stringhe.
La Variante A vince il torneo ogni volta. La Variante B porta conoscenza parziale preziosa che il crossover avrebbe potuto combinare con un altro specialista sulle stringhe — ma non supera mai il primo turno.
La selezione a torneo tratta il miglioramento dei programmi come una singola dimensione. I programmi reali falliscono lungo molte dimensioni contemporaneamente.
Lexicase: tenere vivi gli stravaganti
La selezione lexicase valuta i candidati un test case alla volta, in ordine casuale, filtrando chiunque non sia tra i migliori a parimerito su quel caso. L’ordine viene rimescolato ad ogni evento di selezione, quindi essere uno specialista su qualunque sottoinsieme di casi è una strategia di sopravvivenza.
Sembra costoso — e su 1.000 test case per problema lo sarebbe. Quindi l’abbiamo accoppiata al down-sampling: ad ogni generazione si usa solo il 10% dei test case. Un 10% diverso ogni generazione, così l’intero test set continua a esercitare pressione nel tempo, solo distribuita.
La combinazione tiene vivi gli specialisti senza il conto in compute del lexicase pieno su set di test pieni.
Dare alla ricerca una bussola più fine
La funzione di fitness originale era la frazione di test case superati. Binaria per caso. Un test che si aspetta [1, 2, 3, 4, 5] premia [1, 2, 3, 4, 6] (una cifra sbagliata) come "hello" (caos semantico).
Quella è informazione di gradiente sprecata. Abbiamo costruito F_E, una funzione di fitness che misura quanto vicino è l’output a quello atteso, per ciascun test case. Per i numeri, la distanza. Per le sequenze, confronto elemento per elemento. Ora “quasi giusto” è un numero diverso da “completamente sbagliato”, e la ricerca può salire la collina giusta invece di trattare tutto il paesaggio come un dirupo.
Cosa abbiamo fatto girare
Quattro LLM lungo lo spettro: GPT-4, ChatGPT, Code Llama 7B, LLaMA 3 8B. Tre problemi PSB2 scelti per varietà di difficoltà. Popolazione di 200 individui (giù da 1.000 — selezione migliore significa meno bisogno di forza bruta), fino a 100 generazioni, 30 ripetizioni ciascuna per robustezza statistica.
Cosa abbiamo ottenuto
11 combinazioni modello-problema su 12 sono migliorate. Non è fortuna.
Qualche dettaglio degno di nota:
- I modelli più piccoli hanno guadagnato di più, di nuovo. Code Llama 7B e LLaMA 3 8B hanno avuto i salti relativi più grandi. Anche GPT-4 ha guadagnato, ma in termini assoluti il suo punto di partenza era già forte.
- Lexicase mantiene davvero la diversità. Si vedeva nelle dinamiche di popolazione — più specialisti distinti che coesistevano per molte generazioni, ricombinandosi via crossover in ibridi che né la selezione a torneo né la self-correction avrebbero mai scoperto.
- Il down-sampling è essenzialmente gratis. Tagliare le valutazioni al 10% dei test case per generazione non ha degradato la qualità della soluzione finale sui nostri problemi. Conta: il GI è molto più deployabile quando il costo per generazione è sopportabile.
- F_E paga di più sui problemi difficili. Quando il seme dell’LLM è già vicino, credito parziale e credito binario convergono. Quando il seme è lontano, F_E dà alla ricerca qualcosa da seguire.
E ancora una volta, il GI batte la self-correction
Abbiamo rifatto il confronto con la self-correction. Stessa conclusione dell’anno scorso, con evidenza più forte: il loop evolutivo trova fix che il modello non trova ri-promptandosi da solo, soprattutto quando il codice originale ha problemi strutturali a cui il modello è cieco.
Se stai già usando self-correction in produzione, questo non è un sostituto — è uno stack. Fai prima self-correct se vuoi; poi esegui il GI sopra. Le due modalità di fallimento sono diverse, e i guadagni si compongono.
Cosa conferma
La lezione di quadro generale non è cambiata da EuroGP 2024, ma si sta facendo più solida: il GI è un amplificatore di capacità. Comprime il divario tra modelli economici e modelli costosi. Un modello da 7B parametri con un loop GI intelligente sopra può arrivare nello stesso quartiere di un modello frontier che gira nudo — a una frazione del costo di inferenza.
Per organizzazioni che non possono permettersi di chiamare GPT-4 ad ogni richiesta di generazione di codice, questa non è una nota a piè di pagina. È il titolo.
Cosa è ancora difficile
Tre limitazioni oneste:
- Dipendenza dall’oracolo. Il GI ha bisogno di un segnale di fitness. Niente test case? Sei bloccato. Generare test automaticamente è un altro problema difficile a parte.
- Scala. PSB2 sono programmi piccoli. Non sappiamo ancora come si comporti su modifiche multi-file a livello di repository.
- Bias della grammatica. Costruire la grammatica delle mutazioni dall’output dell’LLM significa che la grammatica eredita i punti ciechi dell’LLM. Se il modello non produce mai un ciclo
while, neanche la ricerca lo esplorerà mai.
Queste sono le prossime cose che inseguiamo.
Reference
Questo post è una sintesi divulgativa di:
Pinna, G., Manzoni, L., De Lorenzo, A., Castelli, M. (2025). Exploring the Effect of Genetic Improvement for Large Language Models generated Code. SN Computer Science, 6(7).
Ricerca condotta presso l’Università degli Studi di Trieste e la NOVA Information Management School (NOVA IMS), Universidade Nova de Lisboa.