
Il paradosso energetico di cui nessuno parla
Ecco una cosa che dovrebbe essere ovvia ma non lo è: quando chiedi a un agente AI di ottimizzare le performance del tuo codice, l’esecuzione dell’agente stesso costa energia. Tanta energia. Spesso più di quanta il codice che sta ottimizzando ne risparmierà mai.
Pensa al conto. L’agente legge file, pianifica, genera codice, esegue test, debugga, itera. Una run reale su una repo non banale divora token a sei cifre. Ora immagina che limi 50ms da una funzione. Quante volte deve essere eseguita quella funzione perché si rientri dell’energia spesa per renderla più veloce?
Per alcuni task: centinaia di migliaia di esecuzioni. Per altri: mai. Alcune “ottimizzazioni” sono perdite energetiche nette.
È una cosa inquietante da scoprire mentre ti dicono che l’AI renderà il software più efficiente.
Perché i default dell’agente sono un cattivo punto di partenza
Gli agenti di codifica AI hanno spazi di configurazione sorprendentemente grandi. Temperatura. Top_p. Token massimi per step. Numero massimo di step. Varianti del prompt template. Queste manopole interagiscono, spesso in modo controintuitivo. Una temperatura più alta può aiutare su task creativi e sprecare budget su quelli semplici. Limiti di step lasco danno all’agente spazio per iterare ma anche per vagare.
I default che vengono shippati con questi agenti sono scelti da umani per medie ragionevoli all’apparenza. Non sono scelti per il tuo task, la tua codebase, il tuo budget energetico. La maggior parte è visibilmente subottimale appena cominci a misurare.
Quindi ci siamo chiesti: e se trattassimo la configurazione dell’agente come un problema di ricerca?
GA4GC: un loop di ricerca sopra l’agente
Il setup è semplice in spirito, complicato nella pratica.
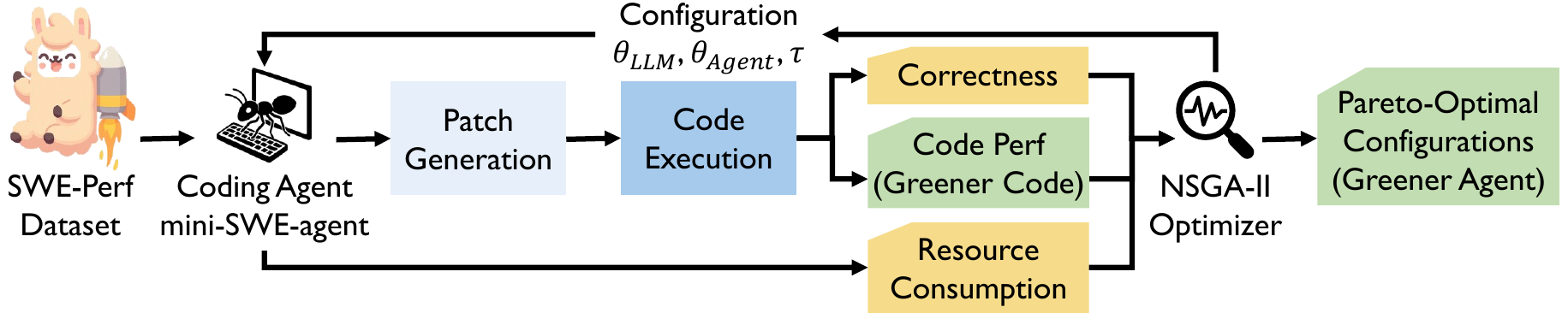
Abbiamo preso un mini-SWE-agent che gira su Gemini 2.5 Pro e abbiamo lasciato che NSGA-II — un algoritmo evolutivo multi-obiettivo — facesse evolvere la sua configurazione. NSGA-II non cerca di trovare una singola configurazione migliore. Mappa una frontiera di Pareto: una frontiera di configurazioni dove non puoi migliorare un obiettivo senza sacrificarne un altro.
Tre obiettivi:
- Minimizza le patch sbagliate. Codice corretto prima di tutto, sempre.
- Massimizza il guadagno di performance. Tutto il punto del task è rendere più veloce il codice target.
- Minimizza il runtime dell’agente. Non lasciare che l’ottimizzatore costi più di quanto valga l’ottimizzazione.
L’agente gira su SWE-Perf, un benchmark di task reali di tuning delle performance dalla libreria Python astropy. Ogni configurazione candidata viene valutata in un ambiente Docker isolato per riproducibilità.
NSGA-II gestisce lo spazio di configurazione eterogeneo — manopole continue (temperatura, top_p), vincoli interi (token massimi, limiti di step), scelte categoriche (prompt template) — applicando gli operatori giusti a ciascuna.
Cosa abbiamo trovato in 25 valutazioni
Sì, 25. È l’intero budget. Il punto di GA4GC non è essere costoso — è essere più economico dell’alternativa di non fare nulla.
Le configurazioni non-dominate hanno ottenuto:
- Riduzione del runtime del 37,7%. Configurazione di default: 1.513 secondi. Migliore configurazione di Pareto: 943 secondi.
- Anche correttezza migliore. Non un trade-off — proprio meglio.
- Miglioramento dell’hypervolume di 135× rispetto alla baseline di default. (L’hypervolume misura quanta parte dello spazio degli obiettivi copre la frontiera di Pareto — più grande è meglio.)
Il titolo: i default non sono solo subottimali, sono pesantemente subottimali. Guadagni significativi sia in qualità che in efficienza sono lì che aspettano chiunque esegua anche solo un piccolo loop di tuning.
La scoperta strutturale che ci ha sorpresi
Abbiamo eseguito una regressione Random Forest per capire quali manopole contano davvero. Due cose sono saltate fuori.
La temperatura domina. Tra tutte le manopole, la temperatura è la singola più importante. Ha un senso intuitivo — modella tutto lo stile esplorativo dell’agente — ma la magnitudine della sua influenza era più grande di quanto ci aspettassimo.
Gli iperparametri dell’LLM guidano la qualità. I vincoli dell’agente guidano il costo. Sono disaccoppiati.
Questa è la scoperta azionabile. Se tuni temperatura e top_p, stai muovendo la manopola di se l’agente produce codice buono. Se tuni i limiti di token e di step, stai muovendo la manopola di quanto ti costa. Le due superfici di controllo non si combattono molto. Puoi ottimizzare qualità e costo quasi indipendentemente — il che, metodologicamente, è ottima notizia.
Tre ricette di deployment
La frontiera di Pareto non è una risposta singola; è un menu. Tre punti utili:
Runtime-critical. Temperatura bassa, top_p restrittivo. Meno creativo, più veloce, economico. Usalo quando ti servono risposte velocemente su task relativamente semplici.
Performance-critical. Temperatura moderata (0,65–0,73), top_p bilanciato. L’agente ha spazio per trovare davvero soluzioni migliori, al costo di più compute. Usalo quando lo speedup che stai cercando di estrarre vale più del runtime dell’agente.
Context-specific. Esegui GA4GC sulla tua codebase e distribuzione di task. Otterrai una frontiera di Pareto cucita sul tuo ambiente, che batte qualunque ricetta generica.
Perché è più di un trucco di benchmark
Mentre gli agenti di codifica AI passano da demo cool a infrastruttura standard, la loro impronta cumulativa di compute diventa una vera questione di sostenibilità. Un’organizzazione che esegue centinaia di task con agenti al giorno sta spendendo soldi seri ed energia seria. La maggior parte è prevenibile.
La lezione qui è che il tuning della configurazione è una leva di sostenibilità, non solo di performance. Non ti serve un modello più piccolo o hardware speciale per rendere il tuo tooling AI più green — ti serve smettere di accettare default che nessuno ha scelto per la tua situazione.
Se stai mettendo in produzione agenti AI, esegui un piccolo loop NSGA-II sul tuo spazio di configurazione prima di scalare. L’energia che risparmierai sarà la sua ricompensa, e la correttezza migliore che otterrai è un effetto collaterale gratuito.
Reference
Questo post è una sintesi divulgativa di:
Pinna, G., Sarro, F. (2025). GA4GC: Greener Agent for Greener Code. In: Proceedings of the 17th Symposium on Search-Based Software Engineering (SSBSE 2025) — Challenge Track on Green SBSE.
Ricerca condotta presso la University College London (UCL) e l’Università degli Studi di Trieste.