
Gli hotfix non sono bug normali
In un qualsiasi progetto software normale, i bug si accodano. Vengono triagiati, prioritizzati, schedulati negli sprint. Alcuni stanno lì per mesi.
Gli hotfix sono i bug che non possono aspettare. L’autenticazione si è rotta. I pagamenti si sono fermati. I dati dei clienti stanno trapelando. La pipeline di rilascio viene bypassata e una patch esce adesso. Sono i bug più costosi da spedire — sia in serate-di-venerdì-tranquille perse, sia in soldi.
Capire la forma dei tuoi hotfix — che tipi di fallimenti continuano a richiedere patch d’emergenza — è enormemente utile. Ti dice dove la tua codebase è fragile, quali categorie di test ti stanno fallendo, quali processi devono cambiare. Lo strumento classico per farlo è una tassonomia dei bug: un modo strutturato per dire “questo hotfix era un memory leak, quello era una race condition”.
Costruire una buona tassonomia automaticamente è difficile. Gli hotfix sono sparsi, le categorie sono selvaggiamente sbilanciate, e l’analisi semantica che serve di solito richiede LLM — che costano soldi veri quando li scali.
Due problemi insieme
Avevamo due motivazioni impilate una sull’altra.
Metodologicamente: possiamo classificare bene gli hotfix nonostante dati minuscoli e classi sbilanciate?
Ambientalmente: possiamo farlo senza bruciare cicli LLM inutili?
Non sono domande separate. Il classificatore più economico è quello che usa meno feature. Quello più accurato è qualunque insieme di feature porti davvero segnale. Se queste due cose si sovrappongono — se alcune feature costano molto e non aiutano — allora entrambi i problemi possono essere risolti contemporaneamente.
Quindi ci siamo posti la domanda ovvia: quali feature contano davvero?
Come funziona HotCat
Usiamo il dataset HotBugs — 88 entry di hotfix su 17 categorie di bug da progetti reali. Per ognuna, raccogliamo tre tipi di feature:
- Feature di codice dal diff stesso (linee aggiunte/rimosse, file modificati, complessità sintattica)
- Metadati di processo da Jira (tempo per risolvere, numero di partecipanti, priorità)
- Riassunti generati da LLM di ogni patch, embeddati con Sentence-BERT, poi organizzati con K-Means
Diciotto feature in totale. Significa 2^18 ≈ 260.000 sottoinsiemi di feature possibili. La selezione manuale è disperata.
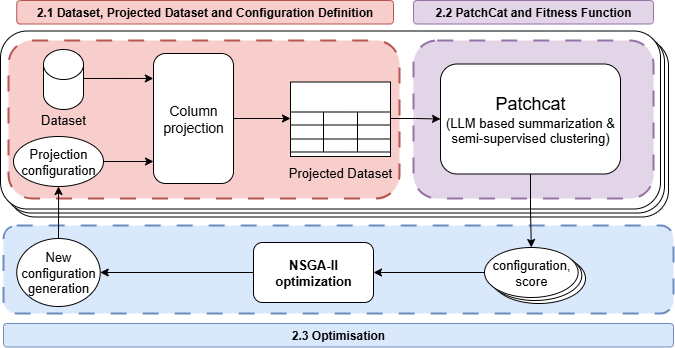
Quindi abbiamo lanciato NSGA-II sopra. Ogni candidato è una maschera binaria sulle 18 feature — tieni o scarta, su ciascuna. Tre obiettivi, ottimizzati congiuntamente:
- Massimizza l’accuratezza di classificazione.
- Massimizza l’NMI (Normalized Mutual Information — robusta allo sbilanciamento delle classi, a differenza dell’accuratezza grezza).
- Minimizza il runtime.
Popolazione di 20, evoluta per 20 generazioni. Piccolissimo per gli standard di NSGA-II. Sufficiente.
I dati sono troppo pochi. Ecco come abbiamo fatto.
88 entry su 17 categorie significa che alcune categorie hanno una manciata di esempi. La generalizzazione sul dataset grezzo si fermava intorno al 55%, che è ai limiti dell’utile.
Abbiamo aggiunto una strategia di data augmentation a due stadi:
- Bilanciamento delle categorie — esempi sintetici per pareggiare le categorie rare.
- Generazione di record post-ottimizzazione — dati aggiuntivi dopo la selezione delle feature, per irrobustire la generalizzazione.
Questo ha portato la generalizzazione dal 55% al 72%. Un salto di 17 punti. La data augmentation non è glamour ma è esattamente quello che serviva qui.
Risultati
La frontiera di Pareto dà un menu, non una risposta. Due punti utili sopra:
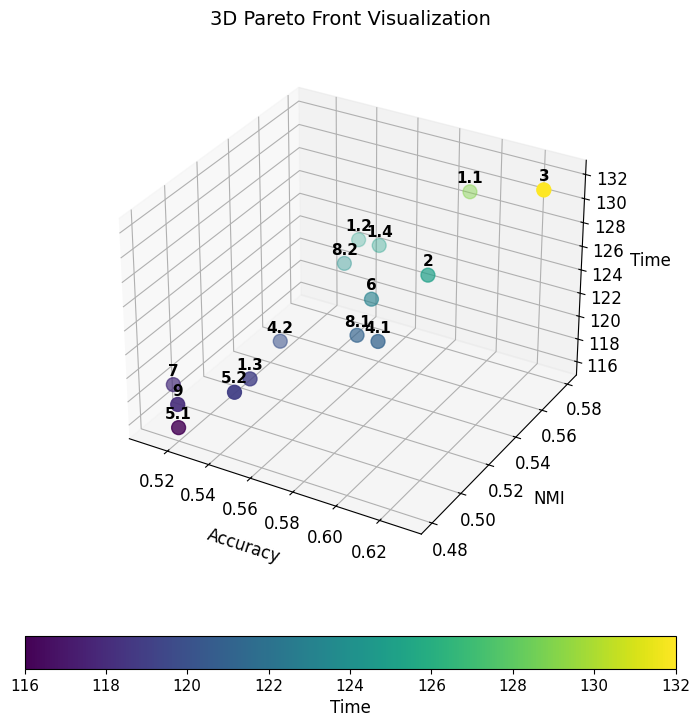
Configurazione bilanciata: 59% di accuratezza, 0,58 NMI, 129 secondi di runtime. Configurazione di massima accuratezza: 63% di accuratezza, 132 secondi — tre secondi in più ti comprano quattro punti di accuratezza.
Il risultato principale è strutturale e un po’ controintuitivo. Alcune feature stavano peggiorando le cose. Rimuoverle selettivamente ha migliorato sia l’accuratezza che il runtime. È il sogno della Green AI: più economico perché è migliore, non nonostante lo sia.
Ribalta anche l’istinto classico della feature engineering. La mossa di default quando la classificazione va male è aggiungere più feature. L’evidenza di HotCat dice: misura prima. Alcune delle feature che hai aggiunto sono rumore, e il rumore fa male.
Perché questo conta oltre gli hotfix
Due insegnamenti vanno oltre questo problema specifico.
L’ottimizzazione multi-obiettivo sullo spazio delle feature è sottoutilizzata. La maggior parte delle pipeline ML tratta la feature engineering come un esercizio umano una tantum. NSGA-II la rende un problema di ricerca continua con trade-off espliciti tra cui scegliere. Quel framing si applica ogni volta che hai molte feature candidate e un vero trade-off costo-qualità.
La Green AI non è una tassa — può essere una guida. Trattare il runtime come obiettivo di prima classe anziché come ripensamento cambia quali feature sopravvivono. Il risultato è più snello e migliore. Mentre gli strumenti di analisi basati su LLM si diffondono nelle pipeline di software engineering, l’organizzazione che si prende la briga di fare questo tipo di tuning pagherà meno e spedirà meglio.
Se stai fissando un task di classificazione con troppe feature e troppo pochi dati, la prossima mossa giusta potrebbe non essere più feature. Potrebbe essere una frontiera di Pareto.
Reference
Questo post è una sintesi divulgativa di:
Pinna, G., Sarro, F. (2025). HotCat: Green and Effective Feature Selection for Hotfix Bug Taxonomy. In: Proceedings of the 17th Symposium on Search-Based Software Engineering (SSBSE 2025) — Challenge Track on Hot Fixing Benchmark.
Ricerca condotta presso la University College London (UCL) e l’Università degli Studi di Trieste.