
The trap of self-correction
Ask any modern LLM to write a Python function and you’ll get something that looks right. Run the tests and you’ll often discover it isn’t.
The reflex is obvious: paste the failing tests back into the chat and ask the model to try again. It’s intuitive, it’s free, and it sometimes works. But it has a ceiling — and the ceiling is the model itself. A model can’t easily debug what it can’t see. Self-correction loops tend to recycle the same blind spots, the same off-by-one errors, the same missed edge cases.
So we asked a different question: what if the LLM is just the first draft?
Code as evolvable material
Genetic Improvement (GI) is a search-based technique that treats programs the way evolution treats genomes. Mutate, recombine, select, repeat. It’s been used to fix bugs and shave runtime out of legacy systems. We wondered if it could rescue LLM code.
The intuition is that LLM-generated code is rarely wildly wrong. It’s usually structurally fine — right data types, sensible algorithm — but with a subtle defect. That makes it a great seed: there are probably good neighbors in the search space, you just need a smart way to find them.
The catch: random mutations on source code almost always produce gibberish that won’t even parse. Our trick was to constrain mutations through a grammar that’s specialized to each program.
The pipeline, in three moves
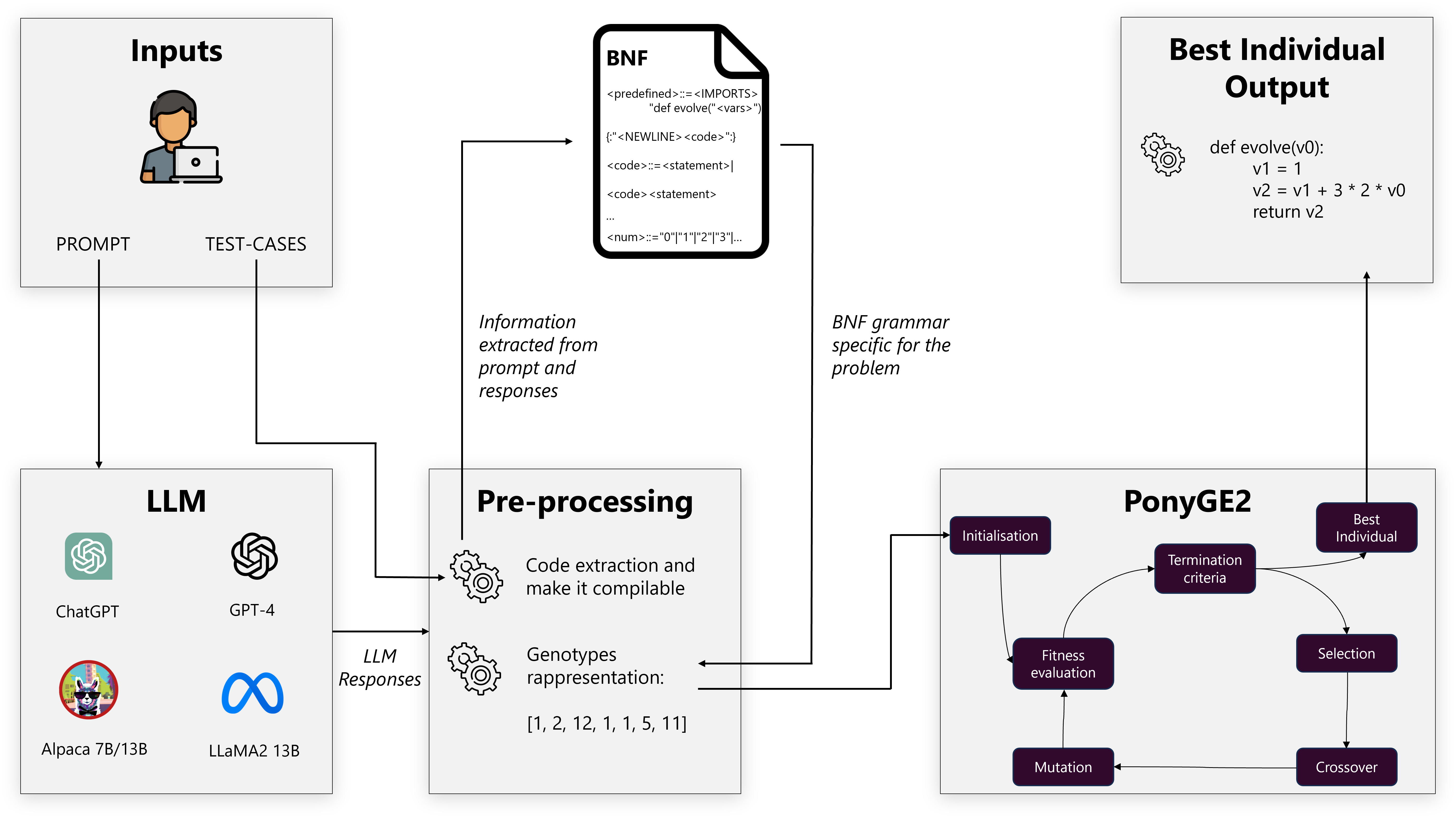
1. Extract. Pull the actual Python out of the LLM’s verbose, markdown-laced reply. Easier said than done — models love to wrap code in prose.
2. Specialize. Parse the code into an Abstract Syntax Tree, then automatically build a BNF grammar from what you see there. Only for loops and integers in the original? Then the grammar only allows for loops and integers. The mutation space stays small and meaningful.
3. Evolve. Hand the seed and grammar to PonyGE2 and let Grammatical Evolution do its thing — population of 1,000, up to 100 generations, fitness = fraction of PSB2 test cases passed.
The dynamic grammar is the secret sauce. A universal grammar for “all valid Python” would explode the search space; a hand-tuned grammar would be brittle. By generating it from the LLM’s own output, we use the model’s draft as prior knowledge about where the right answer probably lives.
What we found
We ran this across 25 PSB2 benchmark problems and five LLMs spanning the capability spectrum: GPT-4, ChatGPT, LLaMA-2, Alpaca-13B, Alpaca-7B. Each experiment was repeated 30 times. Wilcoxon signed-rank tests for significance.
The summary is short:
- Every model improved. Statistically significant (p < 0.001) across the board.
- Smaller models gained the most. Alpaca-7B problems went from “0 tests passing” to “actually working” in many cases.
- Even GPT-4 benefited. Smaller absolute gains, because the seed was already strong, but still real.
- GI beat self-correction. Same starting code, same test feedback — evolution found better fixes than asking the model to try again.
That last point is the one I’d put on a billboard. Self-correction is bounded by the model’s own representation of the problem. Evolutionary search isn’t.
Why this works
Three things, stacked:
The seed is good enough. LLMs give you the right shape of solution. You don’t need to invent the algorithm — you need to nudge it.
The grammar focuses the search. Tailoring mutations to what the program actually contains kills 99% of the search space — the part that was never going to help anyway.
Populations don’t get stuck. Greedy “fix this one bug” approaches dead-end in local optima. A population keeps multiple bets alive and can recombine partial wins through crossover.
What it suggests
If you ship LLM-generated code, this hints that the right pipeline isn’t prompt → output → ship. It’s prompt → output → optimize → ship. The optimization stage doesn’t need a bigger model or more tokens — it needs a search loop with a smart fitness function.
And there’s a bigger picture here: neural and evolutionary methods aren’t competitors, they’re complements. LLMs are fast, fluent, and creative; evolution is patient, systematic, and goal-directed. Stack them, and you get something neither does alone.
Reference
This post is a divulgative summary of:
Pinna, G., Ravalico, D., Rovito, L., Manzoni, L., De Lorenzo, A. (2024). Improving Large Language Models Code Generation by Leveraging Genetic Improvement. In: Proceedings of the 27th European Conference on Genetic Programming (EuroGP 2024), part of EvoStar 2024, Aberystwyth, UK, April 3–5.
Research conducted at the University of Trieste and NOVA Information Management School (NOVA IMS), Universidade Nova de Lisboa.