
The part of a PR nobody measures
When we benchmark AI coding agents, we measure code. Does it compile? Does it pass the tests? Is it clean?
But a pull request is not a diff. It’s a diff plus a story. The reviewer reads the title, then the description, then maybe the code. The description sets expectations. It tells the reviewer what to look for. If the story is wrong, every line of code that follows is being read against the wrong template.
A PR titled “fixed the auth bug” that actually refactors the database layer doesn’t just fail to inform. It actively misleads. And when reviewers detect that mismatch — even subconsciously — trust collapses.
Why agents are weirdly bad at this
Writing code and writing an honest summary of what you just wrote are different cognitive tasks. The first is algorithmic. The second is meta-cognitive — you have to know what you intended, what you tried, and what actually came out the other end.
AI agents are good at the first. They struggle at the second, and the failure has a specific shape:
- The agent reads the task and forms a plan.
- It hits unexpected friction — failing tests, weird dependencies, edge cases.
- It iterates, debugs, takes detours, makes compromises.
- The final code is not quite what the plan was.
- When asked to write a description, the agent often describes the plan, not the result.
That’s where message-code inconsistency is born. Not malice. Not laziness. A drift between intent and outcome that the agent never noticed.
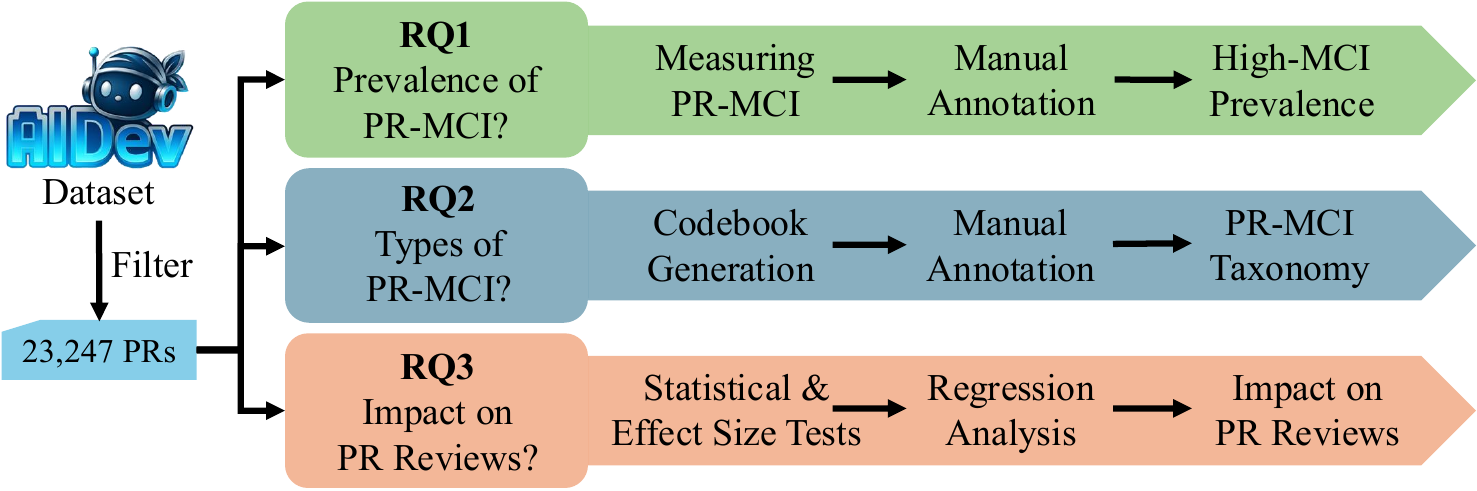
How we measured it
We built a metric — PR-MCI, Pull Request Message-Code Inconsistency — that measures the semantic distance between what the description says and what the diff actually does. It’s a continuous score, not a yes/no, so we can rank PRs by how inconsistent they are.
Then we ran it across 23,247 AI-authored pull requests and looked at what happened to the inconsistent ones.
The 1.7% problem
Only 1.7% of PRs scored as highly inconsistent. That sounds like a non-issue. It’s not, for two reasons.
First, scale. In a company shipping thousands of agent-authored PRs a month, 1.7% is dozens of misleading descriptions per week dropping into reviewer inboxes.
Second, each one is expensive.
The high-inconsistency PRs:
- Get accepted 51.7% less often than consistent PRs
- Take 3.5× longer to merge when they do get accepted
- Often have technically fine code — the rejection is about the story, not the substance
A reviewer who finds that the description lied to them does not give the agent the benefit of the doubt on the next paragraph, or the next file, or the next PR. Trust is paid in advance and refunded slowly.
Why the cost is so high
Two mechanisms compound:
Re-orientation cost. A reviewer who expected auth fixes and found database refactors has to throw away their mental model and build a new one. That’s the most expensive operation in code review. It also tends to surface defensive instincts: “what else is in here that I didn’t expect?”
Trust contagion. If the description is wrong, the reviewer no longer trusts the description as a summary — meaning they have to read the code more carefully than they would have. Every PR after the first inconsistent one inherits a slight discount on trust, especially if it came from the same agent.
The end result: a small percentage of misleading PRs degrades the throughput of the entire review pipeline.
What to do about it
For agent developers, the fix is structural. The description should not be generated from the plan. It should be generated from the final diff, in a separate pass, by something that hasn’t seen the original task. Cheap interventions that already help:
- Verification pass. A second LLM call reads the diff and the description and flags the mismatch.
- Heuristic checks. Files mentioned in the description should appear in the diff. Stated bug categories should match the test failures being touched.
- Description regeneration. Throw away the description the agent wrote during planning. Generate a new one from the final diff alone.
For teams using these agents: assume descriptions are unreliable until proven otherwise. Build a habit of skimming the diff first, the description second.
For the field: stop evaluating agents only on code. A pull request is a deliverable, and the description is part of the deliverable. An agent that writes correct code with a misleading PR is not a good agent — it’s a fast way to destroy reviewer trust.
The real story
As agents become less assistants and more autonomous contributors, the bottleneck shifts. It’s not whether they can write code. They can. The question is whether they can be trusted to describe what they wrote.
Right now, on 1.7% of attempts, they can’t. And that 1.7% is doing more damage to the relationship between humans and agents than any compile error ever could.
Reference
This post is a divulgative summary of:
Pinna, G., Sarro, F., Sutton, C. (2026). Analyzing Message-Code Inconsistency in AI Coding Agent-Authored Pull Requests. In: Proceedings of the 23rd International Conference on Mining Software Repositories (MSR 2026) — Mining Challenge Track.
Research conducted at University College London (UCL) and King’s College London.