
The energy paradox nobody talks about
Here’s a thing that should be obvious but isn’t: when you ask an AI agent to optimize the performance of your code, the agent’s own execution costs energy. A lot of energy. Often more than the code it’s optimizing will ever save.
Think about the math. The agent reads files, plans, generates code, runs tests, debugs, iterates. A real run on a non-trivial repo eats six figures of tokens. Now suppose it shaves 50ms off a function. How many times does that function need to run to break even on the energy spent making it faster?
For some tasks: hundreds of thousands of runs. For others: never. Some “optimizations” are net energy losses.
That’s an unsettling thing to discover when you’re being told AI is going to make software more efficient.
Why the agent’s defaults are a bad starting point
AI coding agents have surprisingly large configuration spaces. Temperature. Top_p. Max tokens per step. Max number of steps. Prompt template variants. These knobs interact, often counterintuitively. Higher temperature can help on creative tasks and waste budget on simple ones. Loose step limits give the agent room to iterate but also room to wander.
The defaults that ship with these agents are picked by humans for reasonable-looking averages. They are not picked for your task, your codebase, or your energy budget. Most of them are visibly suboptimal once you actually measure.
So we asked: what if we treat agent configuration as a search problem?
GA4GC: a search loop on top of the agent
The setup is simple in spirit, gnarly in practice.
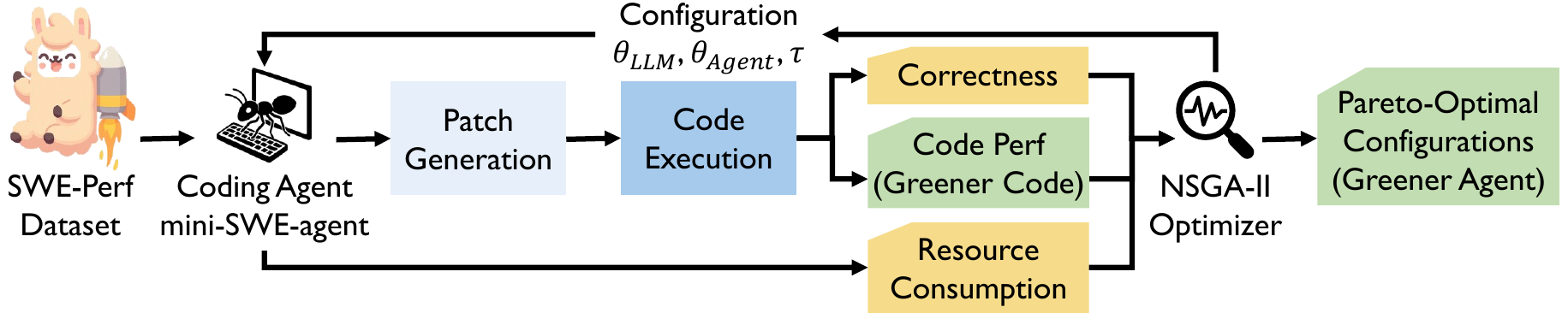
We took a mini-SWE-agent running on Gemini 2.5 Pro and let NSGA-II — a multi-objective evolutionary algorithm — evolve its configuration. NSGA-II doesn’t try to find a single best config. It maps out a Pareto front: a frontier of configs where you can’t improve one objective without sacrificing another.
Three objectives:
- Minimize incorrect patches. Correct code first, always.
- Maximize performance gain. The whole point of the task is to make the target code faster.
- Minimize agent runtime. Don’t let the optimizer cost more than the optimization is worth.
The agent runs on SWE-Perf, a benchmark of real performance-tuning tasks from the astropy Python library. Each candidate config is evaluated in an isolated Docker environment for reproducibility.
NSGA-II handles the heterogeneous configuration space — continuous knobs (temperature, top_p), integer constraints (max tokens, step limits), categorical choices (prompt templates) — by applying the right operators to each.
What we found in 25 evaluations
Yes, 25. That’s the entire budget. The point of GA4GC isn’t to be expensive — it’s to be cheaper than the alternative of doing nothing.
The non-dominated configurations achieved:
- 37.7% runtime reduction. Default config: 1,513 seconds. Best Pareto config: 943 seconds.
- Better correctness too. Not a tradeoff — actually better.
- 135× hypervolume improvement over the default baseline. (Hypervolume measures how much of the objective space the Pareto front covers — bigger is better.)
The headline: the defaults aren’t just suboptimal, they’re badly suboptimal. Significant gains in both quality and efficiency are sitting there waiting for anyone who runs even a tiny tuning loop.
The structural finding that surprised us
We ran a Random Forest regression to figure out which knobs actually matter. Two things popped out.
Temperature dominates. Of all the knobs, temperature is the single most important one. That makes intuitive sense — it shapes the agent’s whole exploration style — but the magnitude of its influence was bigger than we expected.
LLM hyperparameters drive quality. Agent constraints drive cost. They’re decoupled.
This is the actionable finding. If you tune temperature and top_p, you’re moving the dial on whether the agent produces good code. If you tune token caps and step limits, you’re moving the dial on how much it costs you. The two control surfaces don’t fight each other much. You can optimize quality and cost almost independently — which, methodologically, is great news.
Three deployment recipes
The Pareto front isn’t a single answer; it’s a menu. Three useful points on it:
Runtime-critical. Low temperature, restrictive top_p. Less creative, faster, cheap. Use when you need answers quickly on relatively straightforward tasks.
Performance-critical. Moderate temperature (0.65–0.73), balanced top_p. The agent has room to actually find better solutions, at the cost of more compute. Use when the speedup you’re trying to extract is worth more than the agent’s runtime.
Context-specific. Run GA4GC on your own codebase and task distribution. You’ll get a Pareto front tailored to your environment, which beats picking from generic recipes.
Why this is more than a benchmarking trick
As AI coding agents move from cool demos to standard infrastructure, their cumulative compute footprint becomes a real sustainability question. An org running hundreds of agent tasks a day is spending serious money and serious energy. Most of it is preventable.
The lesson here is that configuration tuning is a sustainability lever, not just a performance one. You don’t need a smaller model or special hardware to make AI tooling greener — you need to stop accepting defaults that nobody picked for your situation.
If you’re shipping AI agents into production, run a small NSGA-II loop on your config space before you scale up. The energy you save will be its own reward, and the better correctness you’ll get is a free side effect.
Reference
This post is a divulgative summary of:
Pinna, G., Sarro, F. (2025). GA4GC: Greener Agent for Greener Code. In: Proceedings of the 17th Symposium on Search-Based Software Engineering (SSBSE 2025) — Challenge Track on Green SBSE.
Research conducted at University College London (UCL) and the University of Trieste.