
Hotfixes are not normal bugs
In any normal software project, bugs queue up. They get triaged, prioritized, scheduled into sprints. Some sit there for months.
Hotfixes are the bugs that don’t get to wait. Authentication broke. Payments stopped. Customer data is leaking. The release pipeline gets bypassed and a patch goes out now. These are the most expensive bugs to ship — both in calm-Friday-evenings lost and in dollars.
Understanding the shape of your hotfixes — what kinds of failures keep needing emergency patches — is enormously useful. It tells you where your codebase is brittle, what testing categories are failing you, what processes need to change. The classic tool for this is a bug taxonomy: a structured way of saying “this hotfix was a memory leak, that one was a race condition.”
Building a good taxonomy automatically is hard. Hotfixes are sparse, the categories are wildly imbalanced, and the semantic analysis you need usually requires LLMs — which cost real money to run at scale.
Two problems at once
We had two motivations stacked on top of each other.
Methodologically: can we classify hotfixes well despite tiny data and class imbalance?
Environmentally: can we do it without burning unnecessary LLM cycles?
These aren’t separate questions. The cheapest classifier is one that uses fewer features. The most accurate one is whatever set of features happens to actually carry signal. If those two things overlap — if some features cost a lot and don’t help — then both problems can be solved at the same time.
So we asked the obvious question: which features actually matter?
How HotCat works
We use the HotBugs dataset — 88 hotfix entries across 17 bug categories from real-world projects. For each, we collect three flavors of features:
- Code-level features from the diff itself (lines added/removed, files changed, syntactic stuff)
- Process metadata from Jira (time to fix, number of participants, priority)
- LLM-generated summaries of each patch, embedded with Sentence-BERT, then organized via K-Means
Eighteen features in total. That gives 2^18 ≈ 260,000 possible feature subsets. Manual selection is hopeless.
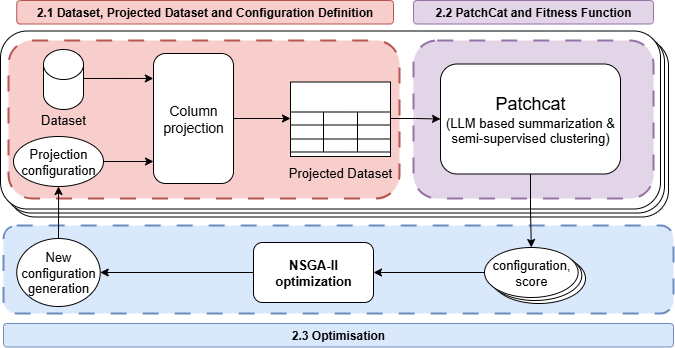
So we threw NSGA-II at it. Each candidate is a binary mask over the 18 features — keep or drop, on each one. Three objectives, optimized jointly:
- Maximize classification accuracy.
- Maximize NMI (Normalized Mutual Information — robust to class imbalance, unlike raw accuracy).
- Minimize runtime.
Population of 20, evolved for 20 generations. Tiny by NSGA-II standards. Sufficient.
The data is too small. Here’s how we coped.
88 entries across 17 categories means some categories have a handful of examples. Generalization on the raw dataset capped at around 55%, which is borderline useful.
We added a two-stage augmentation strategy:
- Category balancing — synthetic examples to even out the rare categories.
- Post-optimization record generation — additional data after feature selection, to harden the generalization.
That brought generalization from 55% to 72%. A 17 point jump. Augmentation isn’t glamorous but it’s exactly what was needed here.
Results
The Pareto front gives a menu, not an answer. Two useful spots on it:
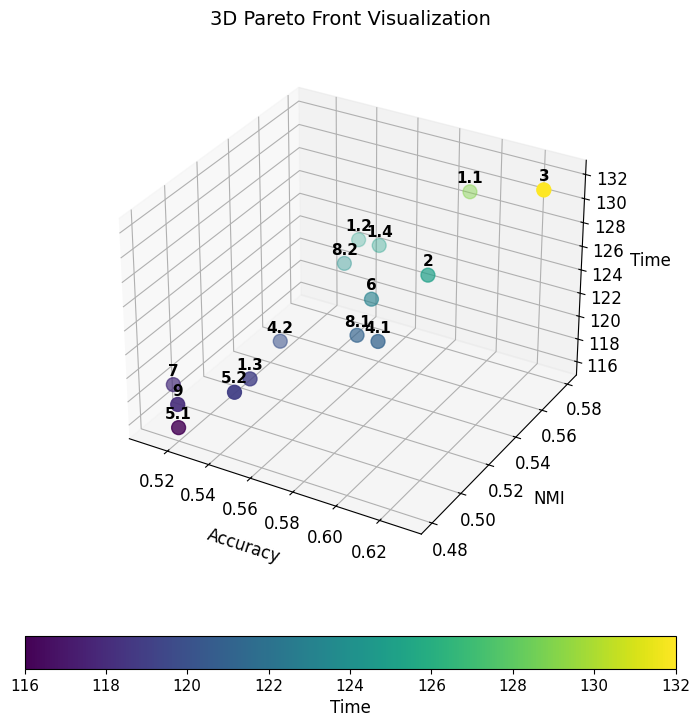
Balanced config: 59% accuracy, 0.58 NMI, 129 seconds runtime. Best-accuracy config: 63% accuracy, 132 seconds — three more seconds buys you four points of accuracy.
The headline finding is structural and a bit counterintuitive. Some features were making things worse. Selectively removing them improved both accuracy and runtime. That’s the Green AI dream: cheaper because it’s better, not in spite of it.
It also flips the usual feature-engineering instinct. The default move when classification underperforms is to add more features. HotCat’s evidence says: measure first. Some of the features you added are noise, and noise hurts.
Why this matters beyond hotfixes
Two takeaways travel beyond this specific problem.
Multi-objective optimization on the feature space is underused. Most ML pipelines treat feature engineering as a one-time human exercise. NSGA-II makes it a continuous search problem with explicit trade-offs you can choose between. That framing applies any time you have many candidate features and a real cost-quality tradeoff.
Green AI is not a tax — it can be a guide. Treating runtime as a first-class objective rather than an afterthought changes which features survive. The result is leaner and better. As LLM-based analysis tools spread through software engineering pipelines, the org that bothers to do this kind of tuning will pay less and ship better.
If you’re staring at a classification task with too many features and not enough data, the right next move might not be more features. It might be a Pareto front.
Reference
This post is a divulgative summary of:
Pinna, G., Sarro, F. (2025). HotCat: Green and Effective Feature Selection for Hotfix Bug Taxonomy. In: Proceedings of the 17th Symposium on Search-Based Software Engineering (SSBSE 2025) — Challenge Track on Hot Fixing Benchmark.
Research conducted at University College London (UCL) and the University of Trieste.