
A democratic problem dressed up as a technical one
Constitutional Court rulings are some of the most important documents a country produces. They define what your government can and can’t do. They shape what your rights are. They are also written by lawyers, for lawyers, in dense Italian legal prose that the average citizen has no chance of understanding.
The Italian Corte Costituzionale already tries to fix this. For each judgment they publish a massima — a condensed summary written by legal experts whose entire job is making case law accessible. Massime are better than full judgments, but they still assume legal literacy most people don’t have.
So the question is straightforward: can an LLM help close the gap? Not by replacing judges or replacing legal experts, but by producing summaries that an ordinary citizen can actually read?
We ran the experiment.
What we tested
Four versions of the same legal content:
- Original judgments (sentenze) — the raw text from the court.
- Expert massime — the human-written summaries, our quality ceiling.
- GPT-4o summaries — generated by prompting OpenAI’s GPT-4o on each judgment.
- Fine-tuned LLaMA 2 7B — a smaller open-source model trained on 10,000 judgment-massima pairs scraped from the Court’s archives.
We also tried Gemma 2B/7B and LLaMantino 7B (an Italian-specialized LLaMA) in the fine-tuning pipeline; LLaMA 2 7B was the best performer, so it represents the open-source side in the human study.
How we measured comprehension
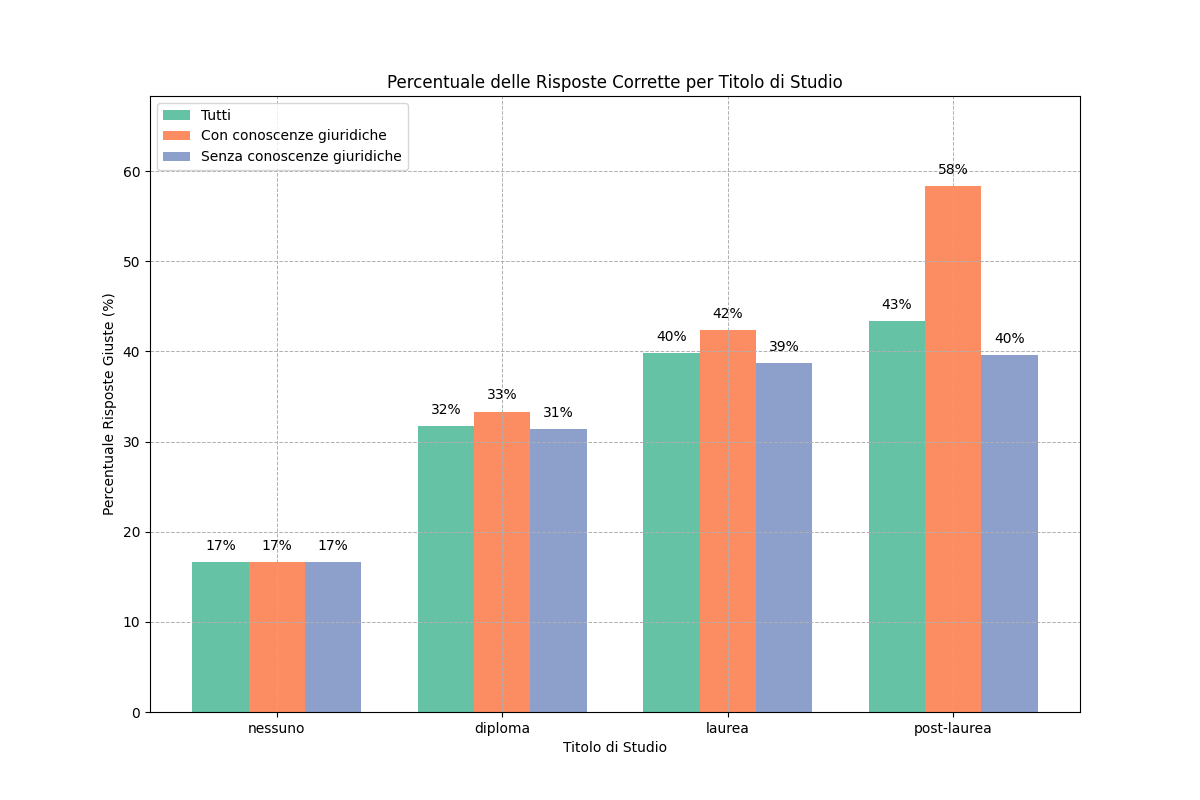
75 participants. Roughly 25% with legal knowledge (law students, professionals), 75% without (general public). Each person read summaries across text types and answered comprehension questions on the actual content.
We ran it as a between-subjects design — each underlying case was seen by each participant in only one of the four formats — to kill learning effects. Differences across formats were tested with chi-squared.
What we found
The headline numbers:
- Expert massime: 45% comprehension. Our ceiling, as expected.
- GPT-4o: 38% comprehension. Significantly better than raw judgments.
- Original judgments: 33% comprehension. The status quo.
- Fine-tuned LLaMA 2 7B: 30% comprehension. Slightly worse than the raw judgment.
That last one is worth a beat. Fine-tuning a small open model on 10,000 expert summaries didn’t help. It hurt. Capacity matters; for this task, 7B parameters appears to be too small to internalize the structural understanding that makes a good massima.
GPT-4o, on the other hand, gives a meaningful 5-point lift over reading the judgment yourself. That’s real.
And then it gets uncomfortable
Here’s the part that should give you pause.
When we looked at which kinds of wrong answers people gave, GPT-4o readers showed a much higher rate of confident incorrectness. They didn’t just misunderstand — they came away with strong, definite, wrong understandings of what the court had ruled.
The text was fluent. Authoritative. Smooth. It read like an expert wrote it. And in the cases where it was wrong, that fluency made the readers more, not less, sure that they understood.
This isn’t unique to legal summarization. It’s the well-known LLM pattern of fluent confabulation. But the stakes change radically when the topic is “what did the constitutional court say about your rights.” A confidently wrong reader of a court ruling is worse than a confused reader of one. Confusion prompts you to ask. Confidence does not.
What educational background did to the picture
Participants with legal knowledge had more uniform comprehension across all text types — they could read the original judgment about as well as the summary. The format mattered less because they brought their own grounding.
Participants without legal knowledge were enormously dependent on the format. They benefited the most from a good summary — and were the most vulnerable to a confidently wrong summary.
In other words: the people LLM summarization is supposed to help are also the people most exposed to its failure modes. That’s the design constraint anyone deploying this kind of tool needs to take seriously.
What to actually do with this
Three concrete takeaways.
For legal-tech builders: LLM summaries of legal text are a real win on accessibility, but raw deployment is dangerous. The right pattern is LLM drafts, expert review — use the model for scale, use the human for accuracy. The cost saving is in reviewing a draft instead of writing one from scratch.
For AI researchers: evaluation metrics that reward fluency and coherence will miss this entire class of failure. We need evaluation methods that probe for confident incorrectness specifically. A summary that reads beautifully but tells you the wrong thing is a worse failure than one that’s clunky but right.
For everyone else: when you read an AI-summarized legal document — or any high-stakes document — calibrate. The confidence in the prose is not evidence of the truth of the prose. The fluency is the package, not the contents.
The bigger picture
The accessibility of legal information is, ultimately, a question of democratic participation. When citizens can’t read the rulings that govern their lives, the principles of transparency and accountability erode. LLMs can help close that gap. They can also, if deployed without care, widen a different gap — the one between what people think they understand and what they actually do.
The technology is ready to assist. It’s not ready to be left alone.
Reference
This post is a divulgative summary of:
Pinna, G., Manzoni, L., De Lorenzo, A., Castelli, M. (2024). From Courts to Comprehension: Can LLMs Make Judgments More Accessible?. In: Proceedings of the 23rd IEEE/WIC International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT 2024), December 2024.
Research conducted at the University of Trieste and NOVA Information Management School (NOVA IMS), Universidade Nova de Lisboa.